Gepubliceerd juni 2026 · Infrastructuurnotities van 3DN
Digitale soevereiniteit wordt vaak in politieke termen besproken — gegevenslocatie, jurisdictie, toeleveringsketens. Voor een kleine hostingoperatie als de onze is het eenvoudiger en concreter: het redeneren dat uw infrastructuur aanstuurt, hoort op hardware te draaien die u beheert, met modellen die u lokaal kunt draaien, gevoed door taken die u inplant — niet door een open chatvenster in iemands anders cloud.
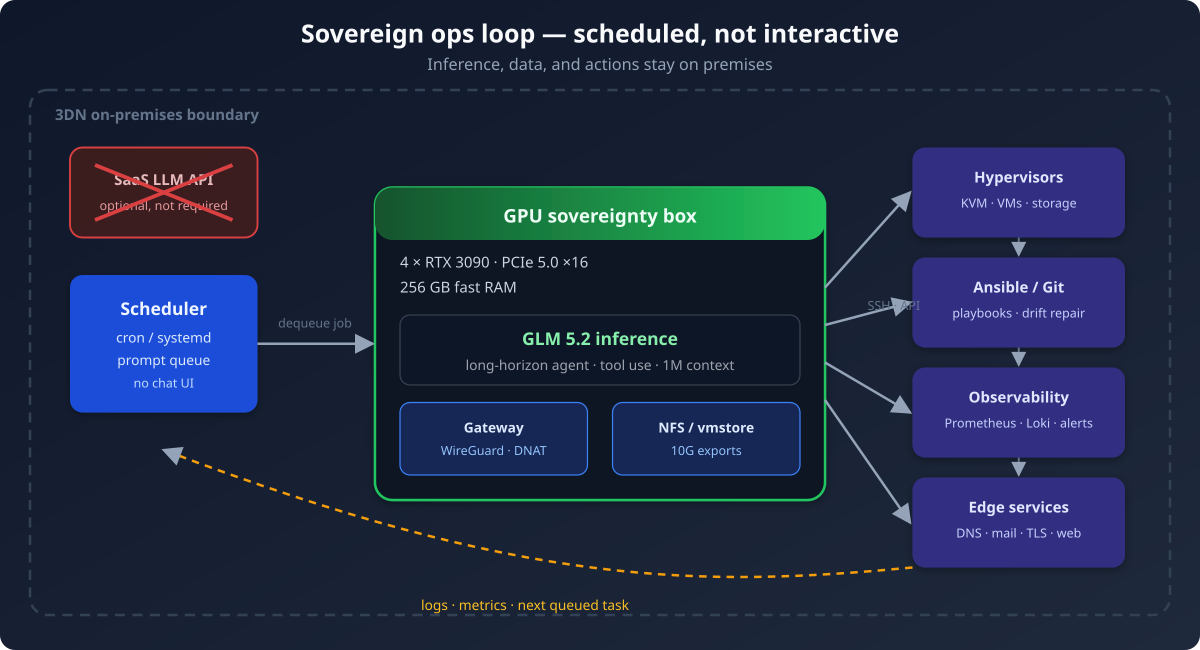
We bouwen naar dat model op één machine: vier NVIDIA RTX 3090 GPU’s, 256 GB snel systeemgeheugen en vier PCIe 5.0 ×16-slots die elke kaart volle bandbreedte geven. Op die box draaien we GLM 5.2 voor gepland serverbeheerwerk. Geen pair programming. Geen Slack-bot. Cron-gestuurde, in de wachtrij geplaatste, controleerbare automatisering die echte productiesystemen raakt.
Waarom soevereiniteit ertoe doet voor ops
Als u een productie-iptables-regelset, een Ansible-inventory of een Patroni-clusterstatus in een gehoste API plakt, verlaten drie dingen meteen uw grens: de data, de inferentie en het auditspoor. Zelfs met enterprise-overeenkomsten vertrouwt u op het bewaarbeleid, de subverwerkers en de definitie van “geen training op uw data” van een andere operator.
Lokale inferentie keert dat om. Prompts, tool-output, SSH-transcripten en playbook-diffs blijven op ons LAN. De modelgewichten staan op schijven die wij bezitten. Als de upstream-API prijzen, limieten of voorwaarden wijzigt, draaien nachtelijke taken gewoon door. Dat is soevereiniteit in de praktijk — geen manifest, maar operationele onafhankelijkheid.
De hardware is het makkelijke deel
Vier RTX 3090’s is een bewuste keuze. Elke kaart heeft 24 GB VRAM; samen bieden ze genoeg ruimte om een groot redeneermodel met tensor-parallelisme of agressieve kwantisatie te bedienen, met capaciteit over voor embedding-werk en batchtaken. 256 GB snel RAM is minstens zo belangrijk: langlopende agenttaken laten KV-cache en scratch-buffers in hostgeheugen lopen, en dezelfde machine fungeert ook als NFS-gateway — zodat VM-images, webroots en back-updoelen op hetzelfde snelle pad liggen als de inferentiestack.
PCIe 5.0 ×16-slots zijn hier geen marketingpraat. Vier GPU’s die door een context van 1M tokens werken, straffen een smalle bus. Elke kaart een volle ×16-lane geven houdt de token-doorvoer voorspelbaar wanneer geplande taken na een incident oplopen.

GLM 5.2 — gebouwd voor lange klussen, niet voor snelle antwoorden
GLM 5.2 is een open-gewicht vlaggenschipmodel dat precies is gericht op het werk dat wij belangrijk vinden: meerstaps engineeringtaken met een echt bruikbaar contextvenster van één miljoen tokens, sterke tool-calling en toonaangevende open-source scores op terminal- en software-engineering-benchmarks. Op ons metaal wordt het een batch systems engineer — iemand die een heel Ansible-repo kan lezen, Prometheus-alertgeschiedenis kan kruisen en een begrensde fix kan voorstellen die onze playbooks respecteert.
Dat laatste punt is belangrijk. Interactieve chat moedigt improvisatie aan. Geplande automatisering moedigt contracten aan: toegestane commando’s, maximale blast radius, verplichte dry-runs en log-appenders die Prometheus kan scrapen.
Geplande acties, geen interactief werk
Het patroon is bewust saai — en dat is een feature.
- Enqueue. ’s Nachts (of na een alert-webhook) komt een taak in een promptwachtrij: “controleer TLS-verloop op alle Thailand-webfronts,” “reconcilieer Galera wsrep-status,” “vacuum journals op util vóór drempel schijfruimte.”
- Dequeue. Een scheduler haalt één taak per keer op. Geen mens achter het toetsenbord; de agent krijgt een vast systeemprompt, repository-checkout en tool-allowlist.
- Execute. GLM 5.2 plant, roept SSH/Ansible/API-tools aan, schrijft artefacten naar schijf en stopt. Sessies zijn hervatbaar; output wordt gelogd.
- Report. Succes of falen komt via dezelfde kanalen als andere automatisering: Loki-logs, Pushover op incidentpaden, Git-commits op playbook-repo’s.
Dit is het tegenovergestelde van “stel de chatbot een vraag.” Het is infrastructure CI voor oordeelsintensieve taken — het soort werk dat vroeger een senior engineer om 02:00 ICT vergde.
Wat “geavanceerd serverbeheer” hier echt betekent
We vragen het model niet onze stack opnieuw uit te vinden. We vragen het binnen onze stack te opereren, met dezelfde guardrails als een menselijke operator:
- Certificaat- en DNS-hygiëne — correleer ACME-vernieuwingsfouten met PowerDNS TSIG-metadata en HAProxy PEM-deployment.
- Opslag- en NFS-migraties — valideer
fstab, NFSv3/v4-redirectgedrag en VM-schijfpaden vóór cutover. - Databaseclustertriage — interpreteer Galera
grastate.dat, los quorum-edge cases op, stel playbook-veilige herstelstappen op. - Gateway- en edge-wijzigingen — redeneer over WireGuard-peers, DNAT-regels en DMZ-topologie zonder configs in een UI van derden te plakken.
- Observability-gestuurde remediatie — maak van een
HostDiskSpaceWarningjournal-vacuum, apt clean en afgekapte logs — met een geschreven incidentnotitie.
Dit zijn geen demoprompts. Het zijn taken waar contextlengte, tool-discipline en naleving van engineeringstandaarden belangrijker zijn dan geestige proza. De long-horizon training van GLM 5.2 is precies daarop gericht.
Wat we niet beweren
Lokale soevereiniteit betekent niet “ontsla het on-call-team” of “schakel menselijke goedkeuring voor productiewijzigingen uit.” Geplande agents hebben nog steeds code review op playbook-diffs, rate limits en falen op manieren die escalatie vereisen. De winst is smaller en waardevoller: uw zwaarste nachtwerk blijft in uw rack, op uw voorwaarden, met uw logs.
De komende maanden neemt deze GPU-box ook gateway- en NFS-taken op in onze Thailand-site — inferentie en infrastructuur-I/O op één soevereine anker. kvm-1 houdt de edge voorlopig; de richting is duidelijk.
Slotgedachte
Digitale soevereiniteit voor een hoster is geen vlag op een kaart. Het is het vermogen om het onderhoudsvenster van morgen te draaien wanneer het internetstemming schommelt, de API-rekening stijgt of de beleidsvoetnoot verandert. Vier RTX 3090’s, 256 GB RAM, GLM 5.2 op PCIe 5.0 en een cronregel die zegt “haal volgende taak op” — dat is een praktisch beeld van hoe onafhankelijkheid er in 2026 uitziet.
Vragen over onze infrastructuur of hostingaanpak? Neem contact op.
Geef een reactie