เผยแพร่ มิถุนายน 2026 · บันทึกโครงสร้างพื้นฐานจาก 3DN
อธิปไตยดิจิทัลมักถูกพูดถึงในแง่การเมือง — ที่ตั้งข้อมูล อำนาจศาล ห่วงโซ่อุปทาน สำหรับผู้ให้บริการโฮสติ้งขนาดเล็กอย่างเรา มันเรียบง่ายและจับต้องได้มากกว่านั้น: การให้เหตุผลที่ขับเคลื่อนโครงสร้างพื้นฐานของคุณควรทำงานบนฮาร์ดแวร์ที่คุณควบคุม ด้วยโมเดลที่รันได้ในเครื่อง ป้อนด้วยงานที่คุณกำหนดเวลา — ไม่ใช่หน้าต่างแชทเปิดในระบบคลาวด์ของคนอื่น
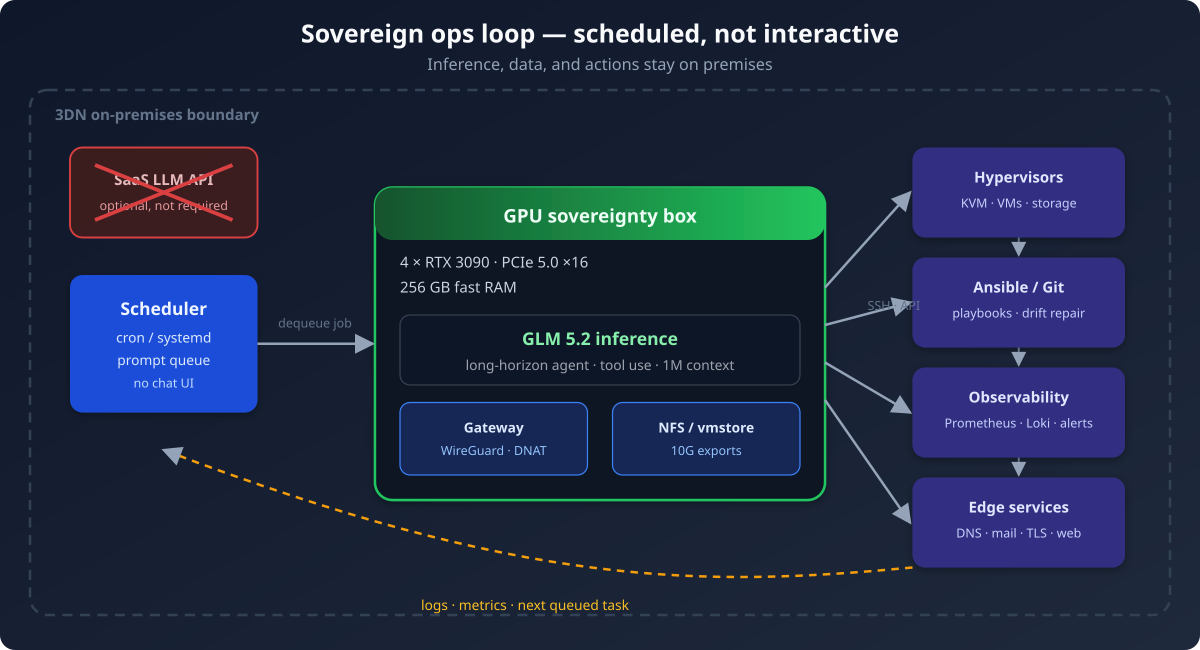
เรากำลังสร้างไปสู่แบบจำลองนั้นบนเครื่องเดียว: GPU NVIDIA RTX 3090 สี่ใบ RAM ระบบเร็ว 256 GB และสล็อต PCIe 5.0 ×16 สี่ช่องที่ให้แบนด์วิดท์เต็มกับการ์ดแต่ละใบ บนกล่องนั้นเรารัน GLM 5.2 สำหรับงานดูแลเซิร์ฟเวอร์แบบกำหนดเวลา ไม่ใช่ pair programming ไม่ใช่ Slack bot เป็นระบบอัตโนมัติที่ cron ขับเคลื่อน คิวงาน และตรวจสอบย้อนกลับได้ ที่สัมผัสระบบโปรดักชันจริง
ทำไมอธิปไตยจึงสำคัญต่องาน ops
เมื่อคุณวางชุดกฎ iptables โปรดักชัน inventory ของ Ansible หรือสถานะคลัสเตอร์ Patroni ลงใน API ที่โฮสต์ไว้ สามสิ่งจะออกนอกขอบเขตของคุณทันที: ข้อมูล การอนุมาน และเส้นทาง audit แม้จะมีข้อตกลงระดับองค์กร คุณก็ยังต้องเชื่อนโยบายการเก็บรักษา ผู้ประมวลผลย่อย และคำจำกัดความ “ไม่ฝึกจากข้อมูลของคุณ” ของผู้ให้บริการรายอื่น
การอนุมานในเครื่องกลับทิศทางนั้น prompt ผลลัพธ์จากเครื่องมือ transcript SSH และ diff ของ playbook อยู่บน LAN ของเรา น้ำหนักโมเดลอยู่บนดิสก์ที่เราเป็นเจ้าของ หาก API ต้นทางเปลี่ยนราคา จำกัดอัตรา หรือเงื่อนไข งานกลางคืนยังรันต่อได้ นั่นคืออธิปไตยในทางปฏิบัติ — ไม่ใช่แถลงการณ์ แต่คือ ความเป็นอิสระในการปฏิบัติการ
ฮาร์ดแวร์คือส่วนที่อธิบายง่าย
RTX 3090 สี่ใบเป็นการเลือกโดยเจตนา การ์ดแต่ละใบมี VRAM 24 GB รวมกันให้พื้นที่เพียงพอสำหรับโมเดลให้เหตุผลขนาดใหญ่ด้วย tensor parallelism หรือการ quantize แบบเข้มข้น พร้อมความจุสำหรับงาน embedding และ batch RAM เร็ว 256 GB สำคัญพอๆ กัน: งาน agent ระยะยาวจะใช้ KV cache และ scratch buffer ในเมมโมรีโฮสต์ และเครื่องเดียวกันยังทำหน้าที่เป็น NFS gateway — ให้ image ของ VM web root และเป้าหมายสำรองอยู่บนเส้นทางเร็วเดียวกับสแตกอนุมาน
สล็อต PCIe 5.0 ×16 ไม่ใช่แค่การตลาด GPU สี่ใบที่เคี้ยว context 1M token จะลงโทษบัสที่แคบ ให้ lane ×16 เต็มกับการ์ดแต่ละใบช่วยให้ throughput ของ token คาดเดาได้เมื่องานที่กำหนดเวลาสะสมหลังเหตุการณ์

GLM 5.2 — สร้างมาสำหรับงานยาว ไม่ใช่คำตอบเร็ว
GLM 5.2 เป็นโมเดล vlaggenschip แบบ open-weight ที่มุ่งตรงกับงานที่เราใส่ใจ: งานวิศวกรรมหลายขั้นตอนพร้อม context window หนึ่งล้าน token ที่ใช้งานได้จริง tool-calling ที่แข็งแกร่ง และคะแนน open-source ชั้นนำบน benchmark ด้าน terminal และ software engineering บนโลหะของเรา มันกลายเป็น วิศวกรระบบแบบ batch — อ่าน repo Ansible ทั้งชุด อ้างอิงประวัติ alert ของ Prometheus และเสนอการแก้ที่จำกัดขอบเขตตาม playbook ของเรา
จุดสุดท้ายนี้สำคัญ แชทแบบโต้ตอบส่งเสริมการ improvis ระบบอัตโนมัติแบบกำหนดเวลาส่งเสริม สัญญา: คำสั่งที่อนุญาต ขอบเขตความเสียหายสูงสุด dry-run บังคับ และ log appender ที่ Prometheus scrape ได้
การกระทำแบบกำหนดเวลา ไม่ใช่งานโต้ตอบ
รูปแบบนี้จงใจให้น่าเบื่อ — และนั่นคือจุดเด่น
- Enqueue. กลางคืน (หรือหลัง webhook alert) งานเข้าคิว prompt: “ตรวจวันหมดอายุ TLS บน web front ไทยทั้งหมด” “กระทบยอดสถานะ Galera wsrep” “vacuum journal บน util ก่อนถึงเกณฑ์ดิสก์”
- Dequeue. scheduler ดึงทีละงาน ไม่มีมนุษย์ที่คีย์บอร์ด agent ได้ system prompt คงที่ checkout repository และ allow-list เครื่องมือ
- Execute. GLM 5.2 วางแผน เรียกเครื่องมือ SSH/Ansible/API เขียน artifact ลงดิสก์ แล้วจบ session ต่อได้ ผลลัพธ์ถูกบันทึก
- Report. สำเร็จหรือล้มเหลวแสดงผ่านช่องทางเดียวกับระบบอัตโนมัติอื่น: log Loki Pushover บนเส้นทาง incident commit Git บน repo playbook
นี่ตรงข้ามกับ “ถาม chatbot” มันคือ infrastructure CI สำหรับงานที่ต้องใช้วิจารณญาณ — งานที่เคยต้องการวิศวกรอาวุโสตอน 02:00 น. ตามเวลา ICT
“การดูแลเซิร์ฟเวอร์ขั้นสูง” หมายถึงอะไรที่นี่
เราไม่ได้ขอให้โมเดลคิดสแตกใหม่ เราขอให้ทำงานภายในสแตกของเรา ด้วย guardrail เดียวกับผู้ปฏิบัติการ:
- สุขอนามัยใบรับรองและ DNS — เชื่อมความล้มเหลวต่ออายุ ACME กับ metadata TSIG ของ PowerDNS และการ deploy PEM ของ HAProxy
- การย้าย storage และ NFS — ตรวจ
fstabพฤติกรรม redirect NFSv3/v4 และ path ดิสก์ VM ก่อน cutover - การคัดกรองคลัสเตอร์ฐานข้อมูล — ตีความ Galera
grastate.datตัดสินกรณี quorum ขอบ และร่างขั้นตอนกู้คืนที่ปลอดภัยต่อ playbook - การเปลี่ยน gateway และ edge — ให้เหตุผลเรื่อง WireGuard peer กฎ DNAT และ topology DMZ โดยไม่วาง config ใน UI ของบุคคลที่สาม
- การแก้ไขจาก observability — เปลี่ยน
HostDiskSpaceWarningเป็น vacuum journal apt clean และตัด log พร้อมบันทึก incident
นี่ไม่ใช่ prompt สาธิต เป็นงานที่ความยาว context วินัยเครื่องมือ และการยึดมาตรฐานวิศวกรรมสำคัญกว่าคำพูดเก่งๆ การฝึก long-horizon ของ GLM 5.2 มุ่งตรงนั้น
สิ่งที่เราไม่ได้อ้าง
อธิปไตยในเครื่องไม่ได้หมายถึง “เลิกจ้างทีม on-call” หรือ “ปิดการอนุมัติจากมนุษย์สำหรับการเปลี่ยนโปรดักชัน” agent ที่กำหนดเวลายังต้องมี code review บน diff playbook rate limit และยังล้มเหลวในลักษณะที่ต้อง escalate ชัยชนะแคบกว่าแต่มีค่ากว่า: งานกลางคืนที่หนักที่สุดของคุณอยู่ในแร็คของคุณ ตามเงื่อนไขของคุณ พร้อม log ของคุณ
ในเดือนข้างหน้า กล่อง GPU นี้จะรับหน้าที่ gateway และ NFS ที่ไซต์ไทยของเราด้วย — รวมอนุมานและ I/O โครงสร้างพื้นฐานบนจุดยึดอธิปไตยเดียว kvm-1 ยังเป็น edge ชั่วคราว ทิศทางชัดเจน
คิดปิดท้าย
อธิปไตยดิจิทัลสำหรับผู้ให้บริการโฮสติ้งไม่ใช่ธงบนแผนที่ คือความสามารถรันหน้าต่างบำรุงรักษาของวันพรุ่งนี้เมื่ออารมณ์อินเทอร์เน็ตเปลี่ยน บิล API พุ่ง หรือ footnote นโยบายเปลี่ยน RTX 3090 สี่ใบ RAM 256 GB GLM 5.2 บน PCIe 5.0 และบรรทัด cron ที่บอก “ดึงงานถัดไป” — นั่นคือภาพปฏิบัติของความเป็นอิสระในปี 2026
มีคำถามเกี่ยวกับโครงสร้างพื้นฐานหรือแนวทางโฮสติ้งของเรา? ติดต่อเรา
ใส่ความเห็น