Published June 2026 · Infrastructure notes from 3DN
Digital sovereignty is often discussed in political terms — data residency, jurisdiction, supply chains. For a small hosting operation like ours, it is simpler and more concrete: the reasoning that runs your infrastructure should live on hardware you control, using models you can run locally, fed by jobs you schedule — not by an open chat window in someone else’s cloud.
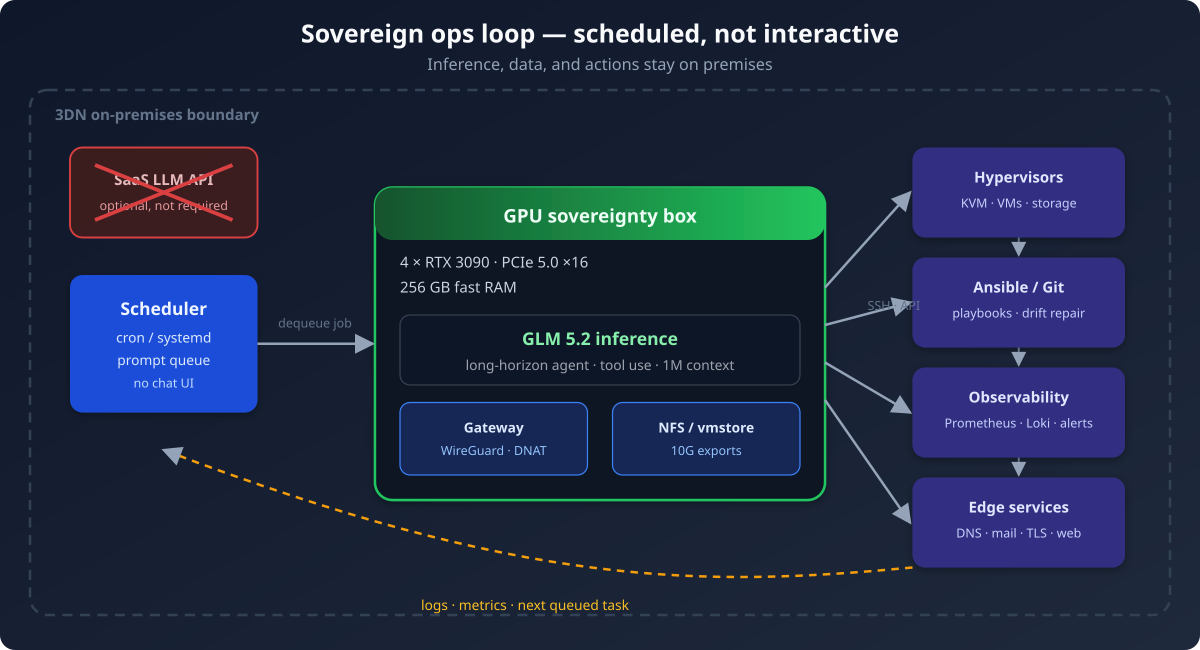
We are building toward that model on a single machine: four NVIDIA RTX 3090 GPUs, 256 GB of fast system RAM, and four PCIe 5.0 ×16 slots that give each card full bandwidth. On that box we run GLM 5.2 for scheduled server-administration work. Not pair programming. Not a Slack bot. Cron-driven, queued, auditable automation that touches real production systems.
Why sovereignty matters for ops
When you paste a production iptables ruleset, an Ansible inventory, or a Patroni cluster state dump into a hosted API, three things leave your boundary immediately: the data, the inference, and the audit trail. Even with enterprise agreements, you are trusting another operator’s retention policy, their subprocessors, and their idea of “no training on your data.”
Local inference reverses that. Prompts, tool output, SSH transcripts, and playbook diffs stay on our LAN. The model weights sit on disks we own. If the upstream API changes pricing, rate limits, or terms, overnight jobs still run. That is sovereignty in practice — not a manifesto, but operational independence.
The hardware is the easy part to describe
Four RTX 3090s is a deliberate choice. Each card carries 24 GB of VRAM; together they provide enough headroom to serve a large reasoning model with tensor parallelism or aggressive quantisation, while leaving capacity for embedding workloads and batch jobs. 256 GB of fast RAM matters just as much: long-horizon agent tasks spill KV cache and scratch buffers into host memory, and the same machine doubles as an NFS gateway — so VM images, web roots, and backup targets land on the same fast path as the inference stack.
PCIe 5.0 ×16 slots are not marketing fluff here. Four GPUs chewing through a 1M-token context will punish a narrow bus. Giving each card a full ×16 lane keeps token throughput predictable when scheduled jobs pile up after an incident.

GLM 5.2 — built for long jobs, not quick replies
GLM 5.2 is an open-weight flagship model aimed at exactly the work we care about: multi-step engineering tasks with a genuinely usable one-million-token context window, strong tool-calling, and benchmark-leading open-source scores on terminal and software-engineering suites. On our metal it becomes a batch systems engineer — one that can read an entire Ansible repo, cross-reference Prometheus alert history, and propose a constrained fix that respects our playbooks.
That last point is important. Interactive chat encourages improvisation. Scheduled automation encourages contracts: allowed commands, maximum blast radius, mandatory dry-runs, and log appenders that Prometheus can scrape.
Scheduled actions, not interactive work
The pattern is deliberately boring — and that is a feature.
- Enqueue. Overnight (or after an alert webhook fires), a job lands in a prompt queue: “review TLS expiry on all Thailand web fronts,” “reconcile Galera wsrep state,” “vacuum journals on util before disk threshold.”
- Dequeue. A scheduler drains one job at a time. No human is at the keyboard; the agent gets a frozen system prompt, repository checkout, and tool allow-list.
- Execute. GLM 5.2 plans, calls SSH/Ansible/API tools, writes artifacts to disk, and exits. Sessions are resumable; output is logged.
- Report. Success or failure surfaces through the same channels as any other automation: Loki logs, Pushover on incident paths, Git commits on playbook repos.
This is the opposite of “ask the chatbot a question.” It is infrastructure CI for judgment-heavy tasks — the kind of work that used to require a senior engineer at 02:00 ICT.
What “highly advanced server admin” actually means here
We are not asking the model to reinvent our stack. We are asking it to operate inside it, with the same guardrails as a human operator:
- Certificate and DNS hygiene — correlate ACME renewal failures with PowerDNS TSIG metadata and HAProxy PEM deployment.
- Storage and NFS migrations — validate
fstab, NFSv3/v4 redirect behaviour, and VM disk paths before cutover. - Database cluster triage — interpret Galera
grastate.dat, arbitrate quorum edge cases, draft playbook-safe recovery steps. - Gateway and edge changes — reason about WireGuard peers, DNAT rules, and DMZ topology without pasting configs into a third-party UI.
- Observability-driven remediation — turn a
HostDiskSpaceWarninginto journal vacuum, apt clean, and truncated logs — with a written incident note.
These are not demo prompts. They are the class of tasks where context length, tool discipline, and engineering standard adherence matter more than witty prose. GLM 5.2’s long-horizon training is aimed precisely there.
What we are not claiming
Local sovereignty does not mean “fire the on-call team” or “disable human approval for production changes.” Scheduled agents still need code review on playbook diffs, still need rate limits, and still fail in ways that require escalation. The win is narrower and more valuable: your hardest overnight work stays inside your rack, on your terms, with your logs.
Over the coming months this GPU box will also absorb gateway and NFS duties in our Thailand site — consolidating inference and infrastructure I/O on one sovereign anchor. kvm-1 keeps the edge for now; the direction is clear.
Closing thought
Digital sovereignty for a hoster is not a flag on a map. It is the ability to run tomorrow’s maintenance window when the internet mood swings, the API bill spikes, or the policy footnote changes. Four RTX 3090s, 256 GB of RAM, GLM 5.2 on PCIe 5.0, and a cron line that says “dequeue next job” — that is a practical picture of what independence looks like in 2026.
Questions about our infrastructure or hosting approach? Get in touch.
Leave a Reply